美国当地时间4月24日,苹果在Hugging Face上放出了自己的开源“小模型”家族——4个预训练的大模型OpenELM。

图源:X
四款模型体量极小,参数量分别为 270M、450M、1.1B和3B。

图源:Hugging Face
在Hugging Face页面上苹果表示,OpenELM(Open-source Efficient Language Models,即“开源高效语言模型”)在诸如电子邮件编写等文本相关任务上,有较高的执行效率。系列模型已经开源,可供开发人员使用。
4月22日发布的相关论文中,研究人员介绍了OpenELM的整个框架,包括数据准备、训练、微调以及测评结果等。

图源:论文
模型是真的开源了,但能力也是真的很一般
一向以封闭著称的苹果,突然在大模型时代以非常激进的姿态加入开源阵营。
这次的OpenELM不但提供模型下载,还开源了和模型相关的非常重要的信息:
模型权重和推理代码
还包括了在公开数据集上进行模型训练和评估的完整框架,涵盖训练日志、多个保存点和预训练设置
开源了CoreNet——深度神经网络训练库
训练库可以使研究人员和工程师能够开发和训练各种标准及创新的小型和大型模型,适用于多种任务,如基础模型(例如,CLIP和大语言模型(LLM))、物体分类、检测以及语义分割。
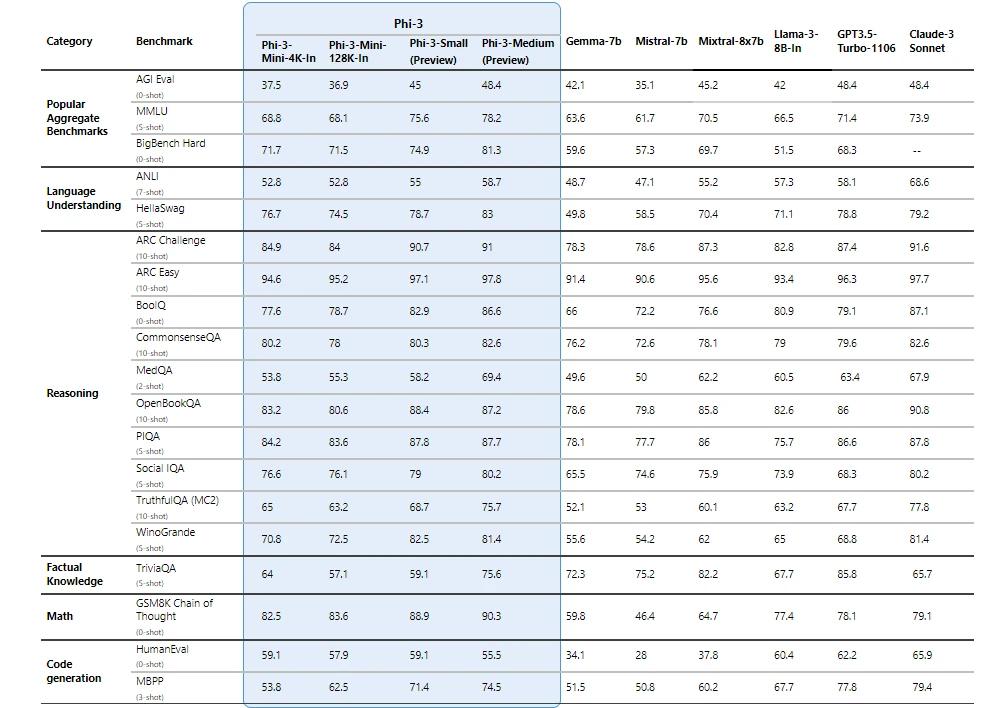
OpenELM采用按层分配参数的策略,有效提升了Transformer模型各层的参数配置效率,显著提高模型准确率。在大约十亿参数的预算下,OpenELM的准确率较OLMo提升了2.36%,且预训练所需的Token数量减少了一半。

图源:论文
论文透露,模型是在128个A100/H100 GPU上进行的训练,最大的模型训练时长为13天。

图源:论文
模型最体量大仅为3B,可以看出,苹果该系列的模型,只针对端侧和桌面级的本地部署设计。
论文也透露,所有的测试平台都是家用级设备:
Intel i9-13900KF CPU, 64 GB内存, 英伟达RTX 4090 GPU,24G显存
Apple MacBook Pro,M2 Max ,64G内存
性能上,模型似乎只是研究目的设计,某些常见测试集上取得的成绩也不高。与微软推出的Phi系列模型等主流SLM相比,差距明显。
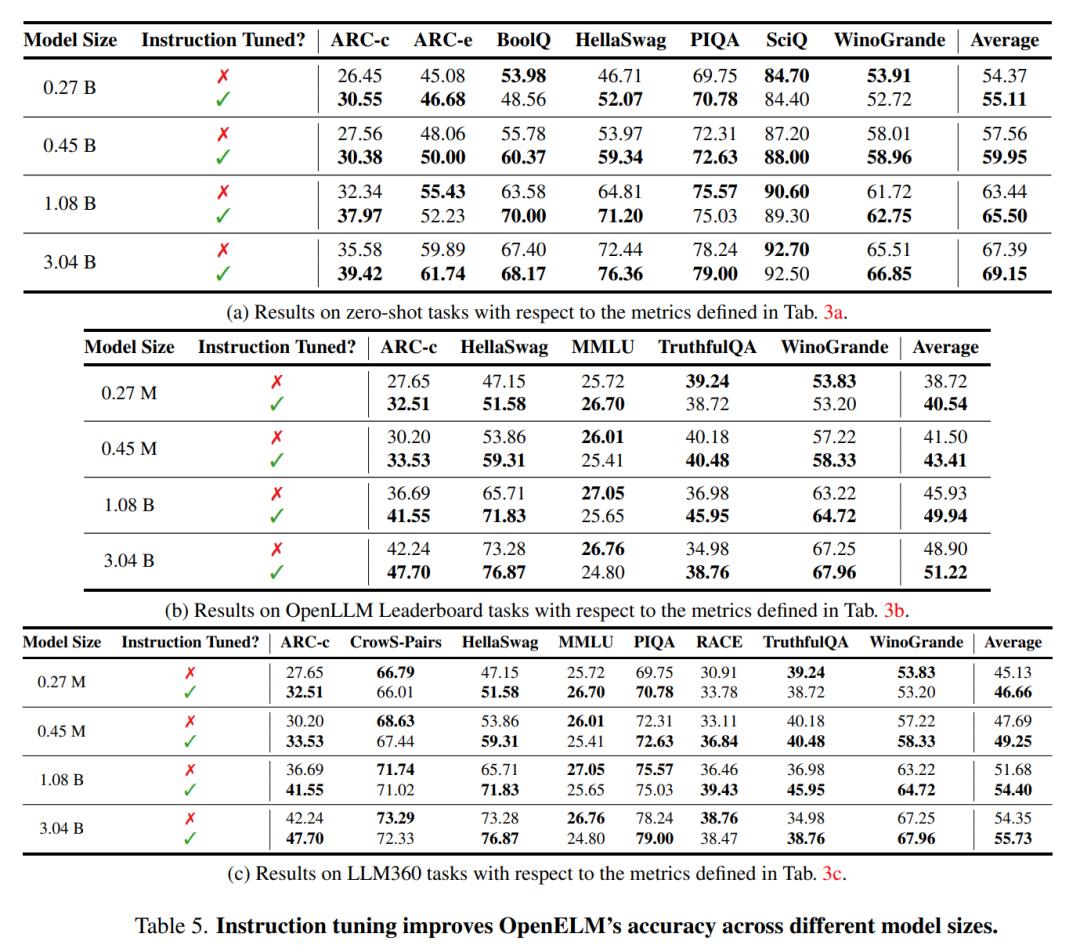
图源:论文
Phi-3在5-shot的MMLU上,可达到70左右的水平,而OpenELM只有不到30.
图源:论文
针对这个问题,网友也对原因进行了一些猜测。
图源:X
用的数据集很小,而且只用了公开的数据集,个人认为,他们只是在对未来训练更大的模型进行针对性的研究。
开源社区的用户们,也第一时间对模型进行了些测试,整体反馈是模型似乎过于“对齐”,换句话来说就是——废话可能有点多。

图源:X

图源:X
从目前开源社区的反馈来看,OpenELM似乎不是一个精心设计和训练后用来秀肌肉的模型,所以性能和表现离同体量最领先的模型差距不小。
论文中,研究人员也没有过于强调模型的能力,而是纠结于准确率和推理性能。
去年已有开源动作,技术实力还待6月亮剑
放弃造车后的苹果,在大模型战争中动作愈发频繁。(见智能涌现文章 苹果300亿参数大模型首亮相,还买了家AI公司)
很多时候,“买买买”是大家对苹果AI布局的主要印象之一。
3月15日,苹果收购了加拿大AI初创公司DarwinAI。自身AI团队一下扩充几十个技术人员。4月23日又曝出,早在去年12月已经悄悄收购巴黎AI初创公司Datakalab。这家2016年成立的公司,亦专注低功耗、高效率的深度学习算法。
苹果最近的这两起收购都围绕端侧大模型展开——比如DarwinAI想把AI系统打造得“小而精”,Datakalab专于低功耗、高效率的深度学习算法,无需依赖云端系统即可运行。
也是在3月,苹果被爆出与谷歌进行谈判,希望将Gemini集成到新的iPhone中。此外,据透露,苹果还与OpenAI进行了讨论,考虑使用其模型。
不只是“招兵买马”,在研究端,起步稍晚的苹果也不忘“卷卷卷”。
2023年10月,苹果发布名为Ferret的开源LLM。这一模型结合了计算机视觉和自然语言处理技术,能识别图像中的对象和区域,将文本转化为视觉元素,并进行图像相关的文本对话。
2024年4月初,基于Ferret,苹果发布多模态大模型(MLLM )Ferret-UI,表现出不凡的UI屏幕理解能力——不仅优于大多数开源UI MLLM,而且在所有基本UI任务上也超过了GPT-4V。

图源:论文
此前,苹果保密原则伴随的封闭生态,一度让外部开发人员无法介入。一开始,Ferret研究没有得到太多关注,其以非商业许可证开源,不能用于商业目的。
但发布两月后的12月底,AI医学非营利组织的运营商Bart De Witte反应过来——原来苹果10月就加入了开源社区,自己没注意到这次重要的发布。

图源:X
也就是在这个时间点上,Ferret又为人热议——这一反苹果此前的保密立场,表明了自身在AI方面的开放态度。
可以说,在今年2月财报发布会上库克公布生成式AI计划之前,苹果自身的AI研究进展就很多了。2023年12月,它推出专门在 Apple 芯片上用于机器学习的开源阵列框架 MLX。2024年2月,又发布图像编辑模型MGIE,让用户无需通过照片编辑软件,就能用简单语言描述他们要在照片中更改的内容。
2024年3月,苹果在论文中介绍的 “MM1”多模态大模型,同样拥有图像识别和自然语言推理能力。不过和其他大模型比起来,MM1的效果不算惊艳。苹果只是围绕MM1开展实验发现影响模型效果的关键因素。
MM1的论文指出,无论是开源还是闭源,现在都没有真正分享达到算法设计经历的过程。所以苹果希望借MM1的研究打破局面,在论文里公开模型训练的种种细节。
同样,OpenELM模型的确彰显了端侧模型的进展,但技术貌似并没有达到外界的预期。
或许,这次苹果通过发布完整的训练、评估框架等,以再次表达“Open”的决心。论文表示:
此次全面发布,希望在增强和巩固开放研究社区,为未来的开放研究工作铺平道路。
所以,OpenELM效果一般,网友还是也会为苹果的开放感到意外。

图源:X
图源:X
苹果真正的AI实力,要等到六月的全球开发者大会(WWDC)才能揭晓。但开源做出的“姿态”,几个月算是表现到位了。
论文重点
模型构架
苹果的研究人员采用了仅包含解码器的Transformer架构,但是作出了一些特殊的调整:
在线性层中不设置可学习的偏置参数
采用RMSNorm进行预归一化,并使用旋转位置嵌入(ROPE)来编码位置信息
用分组查询注意力(GQA)来替代传统的多头注意力(MHA)
将传统的前馈网络(FFN)更换为SwiGLU FFN
采用闪电注意力机制计算缩放点积注意力
使用与LLama相同的Tokenizer进行文本处理
OpenELM与传统的大语言模型的最大不同在于,通常大模型在每一层Transformer中使用相同配置,而OpenELM为每层设置了不同的配置(如头数和前馈网络的尺寸),使每层的参数数量各不相同。
这种方法,让OpenELM能更有效地利用参数预算,从而达到更高模型准确率。通过“层间缩放”(也称为块间缩放),实现了这一层间参数的非均匀分配。
预训练数据和训练细节
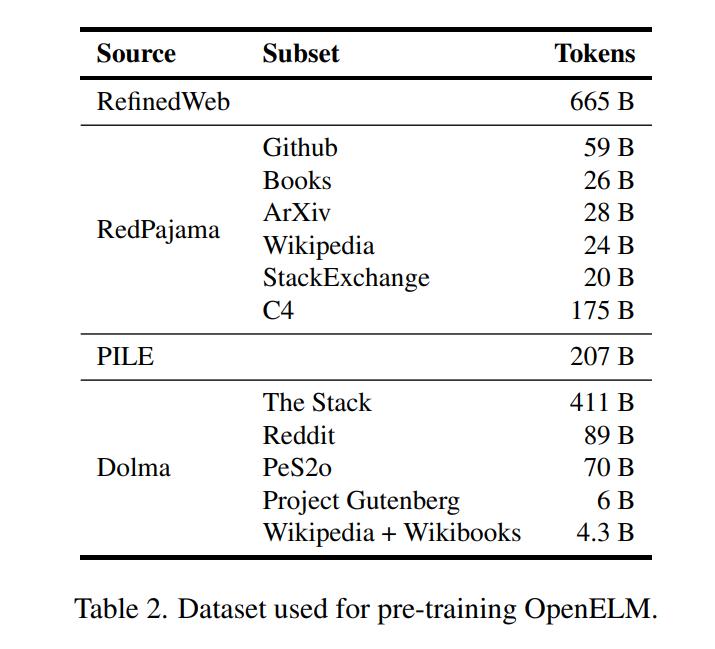
研究人员只使用了公开的数据集进行预训练。
具体包括RefinedWeb、去重后的PILE、RedPajama和Dolma v1.6的部分数据,总计约1.8万亿Token。
从苹果提供的公开数据来源来看,数据包括了像arXiv,维基百科,Reddit,GitHub等各种主流的网络社区和百科知识平台。
图源:论文
值得一提的是,苹果没有采用预先分词(pretokenized)的数据,而用了即时过滤和分词的方式处理文本数据。这种做法,使研究人员能够轻松地尝试各种tokenizer,极大简化了原型设计和研究过程。实验中,他们就采用了与LLama相同的tokenizer。
训练结果
研究人员将OpenELM与一些公开的大语言模型进行了对比,包括PyThia、Cerebras-GPT、TinyLlama、OpenLM、MobiLlama和OLMo。

图源:论文
性能与OpenELM最接近的,是MobiLlama和OLMo。这两个模型都是在更大规模的数据集上进行预训练的。
从上图中可以看出,OpenELM的准确度随着训练迭代次数的增加而提升,在多数任务中都表现出明显的准确率增长。
此外,通过对最后五个检查点的平均处理(这些检查点是每隔5000次迭代收集一次),显示出与350k次迭代后获得的最终检查点相当或略优的准确率。

图源:论文
上图实验结果显示,OpenELM在各种评估框架中。都显示出超越现有方法的有效性。例如,一个拥有11亿参数的OpenELM变体,在与拥有12亿参数的OLMo比较时,在不同的评估中准确率分别提高了1.28%、2.36%和1.72%,而且这是在使用不到一半的预训练数据的情况下实现的。

图源:论文
指令微调之后,上图的结果表明,指令微调在不同的评估框架中,一致地提高了OpenELM的平均准确率,提升幅度为1-2%。
推理性能表现
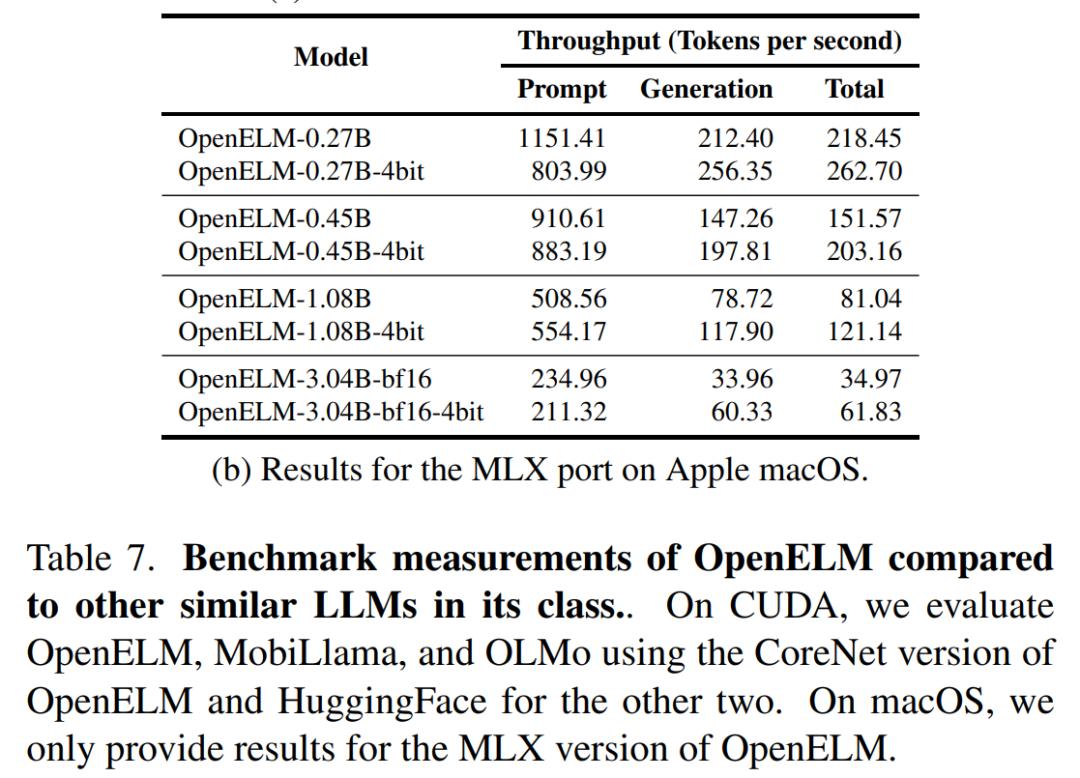
研究人员主要测试了模型在两个文章开头介绍过的PC和Mac两个平台上的推理性能表现。
可以看出,代表着Mac主流配置的M2 Max平台,在跑3B模型时推理性能可以达到每秒34 token,已基本超过人类的阅读速度。
图源:论文
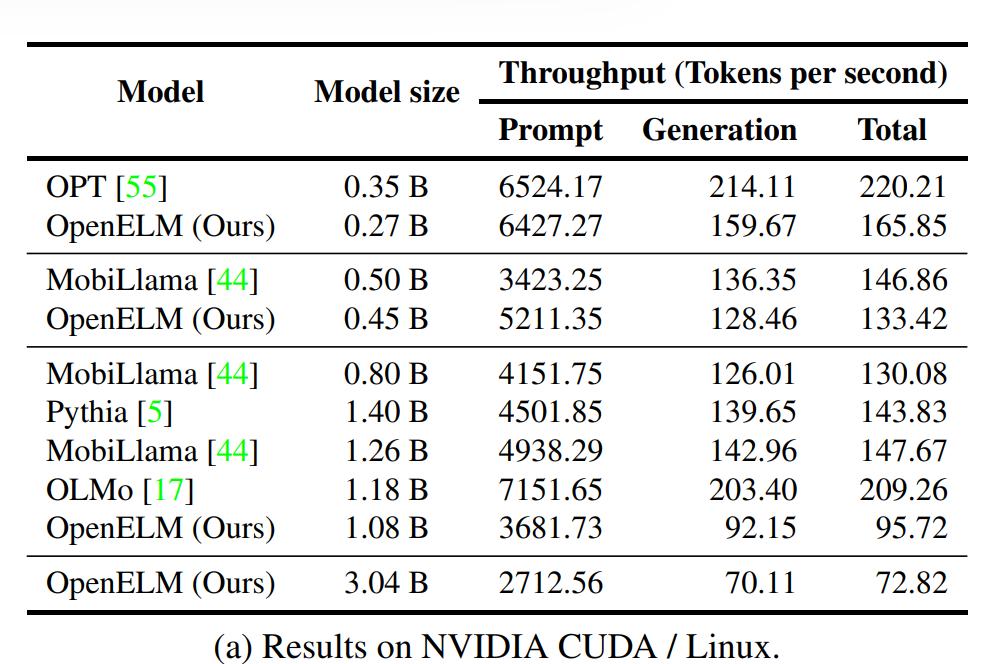
在最顶级的PC配置下,3B模型的推理速度达到了70.
图源:论文
尽管OpenELM在相似参数量下具有更高的准确性,但是它的推理速度比OLMo慢。
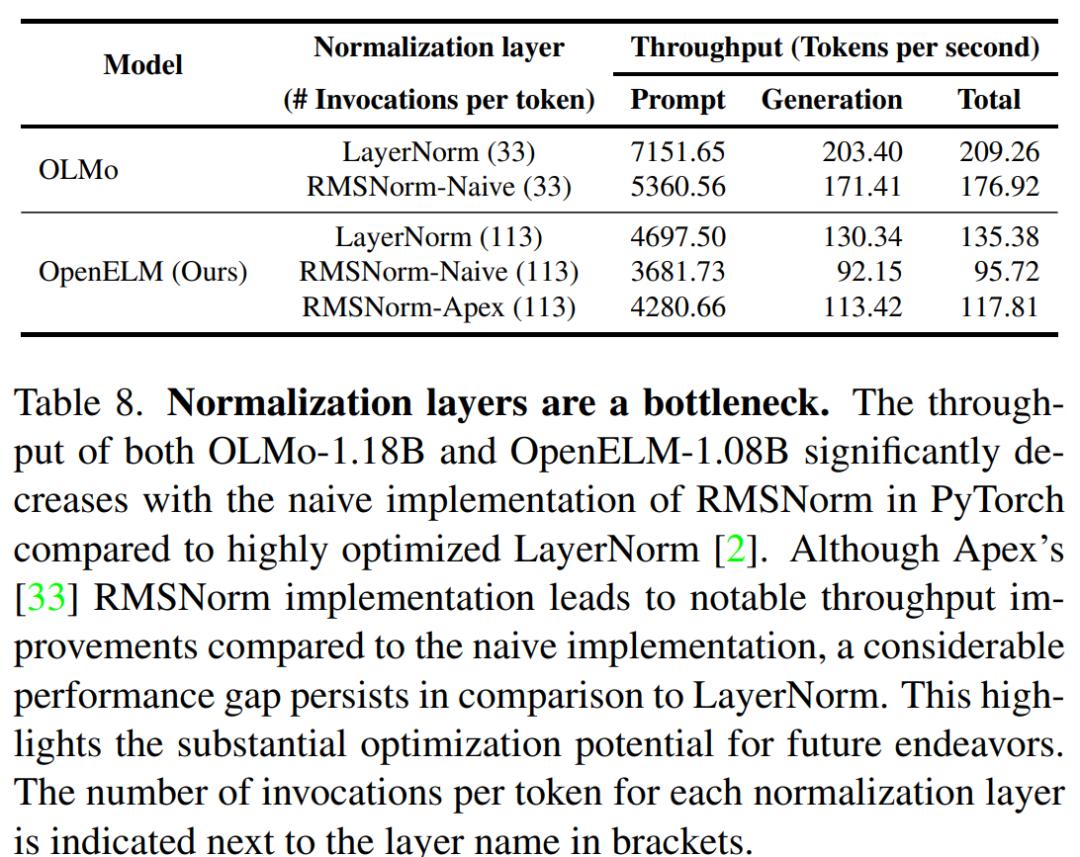
分析显示,OpenELM处理时间的一个重要部分,可以归因于RMSNorm的初级实现(下图所示)。
图源:论文
具体来说,初级RMSNorm的实现,导致许多单独的内核启动,每个内核处理少量输入,而不是像使用LayerNorm那样启动单个融合内核。
通过将初级RMSNorm替换为Apex的RMSNorm ,OpenELM的推理速度显著增加。
然而,与使用优化过的LayerNorm的模型相比,仍然存在显著的性能差距,部分原因是:
OpenELM有113个RMSNorm层,而OLMo有33个LayerNorm层
Apex的RMSNorm对小输入未进行优化
为了进一步说明由于RMSNorm造成的性能下降,研究人员将OLMo中的LayerNorm替换为RMSNorm,观察到生成吞吐量显著下降。在未来的工作中,研究人员计划探索优化策略,以进一步提高OpenELM的推理效率。


_20240425180811_186.jpg)
